Every modern enterprise is moving from an organization run by software to one orchestrated by AI, creating a tension between velocity and control. To resolve this tension, organizations require a unified architecture. Today, we are announcing the general availability of the Prisma AIRS AI Gateway, the AI control plane for the enterprise.
The shift from static LLMs to autonomous agents has fundamentally changed the global threat surface. Frontier models like Anthropic's Mythos can now autonomously discover hundreds...
When a major cyber incident hits, all eyes are on the CISO. They become the invisible CEO of crisis, steering the entire enterprise through the storm, managing stakeholders and mak...
The rise of Agentic AI is rapidly reshaping the enterprise, yet its deployment opens a complex new frontier for cyber threats. As organizations race to harness the power of enterp...
AI-assisted attack cycles are compressing the time between vulnerability disclosure and exploitation from weeks into minutes. In most OT environments,...
In the modern IT environment, an "export" is triggered not only by physical shipment but also by the electronic transmission of controlled data across...
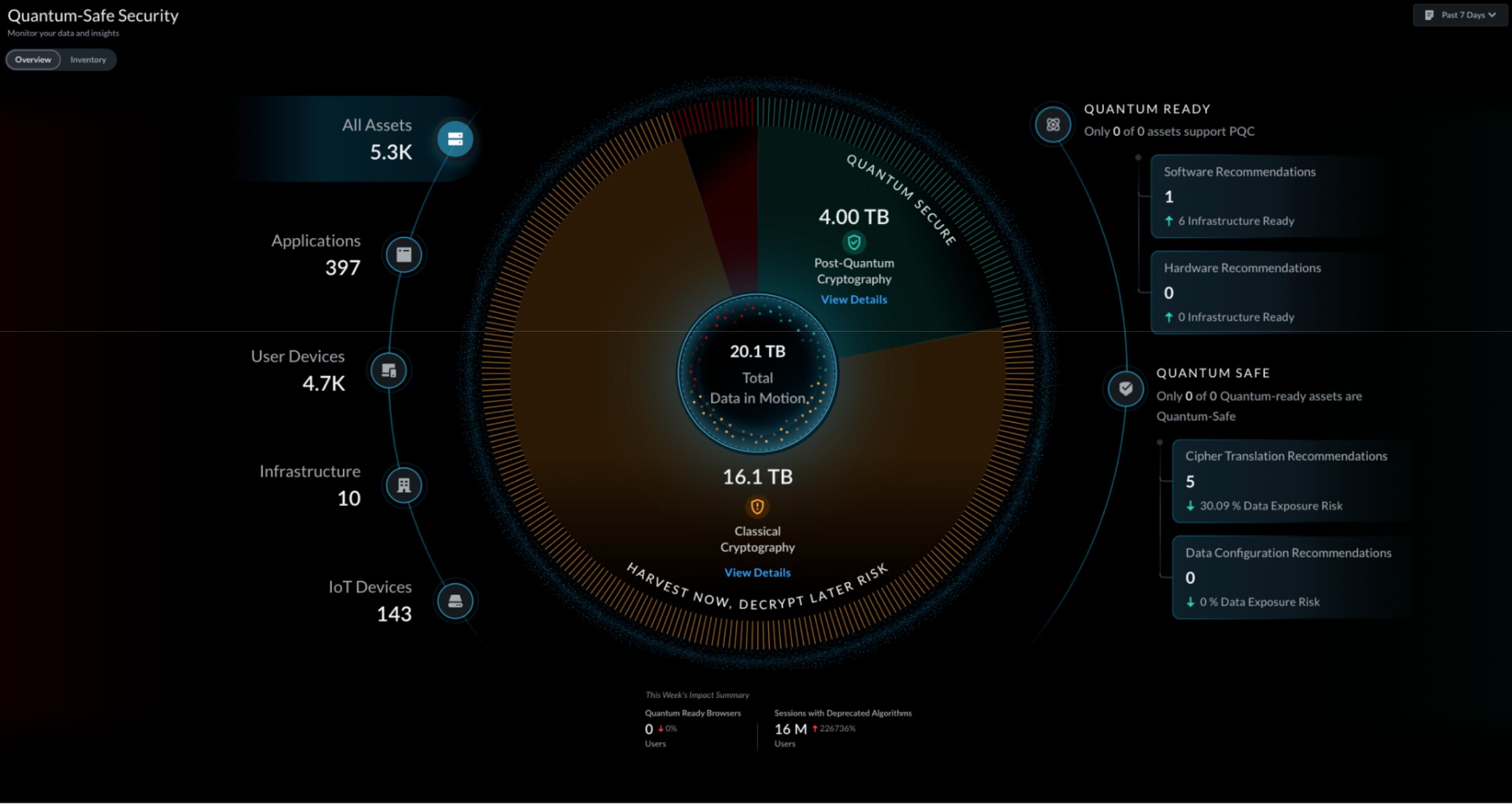
The reality of quantum computing is no longer a distant academic theory; it is an impending shift that demands immediate action from cybersecurity lea...
AI agents can now read your employees’ laptops. Here’s what that means for data security and why Endpoint DLP can no longer treat local storage as a s...
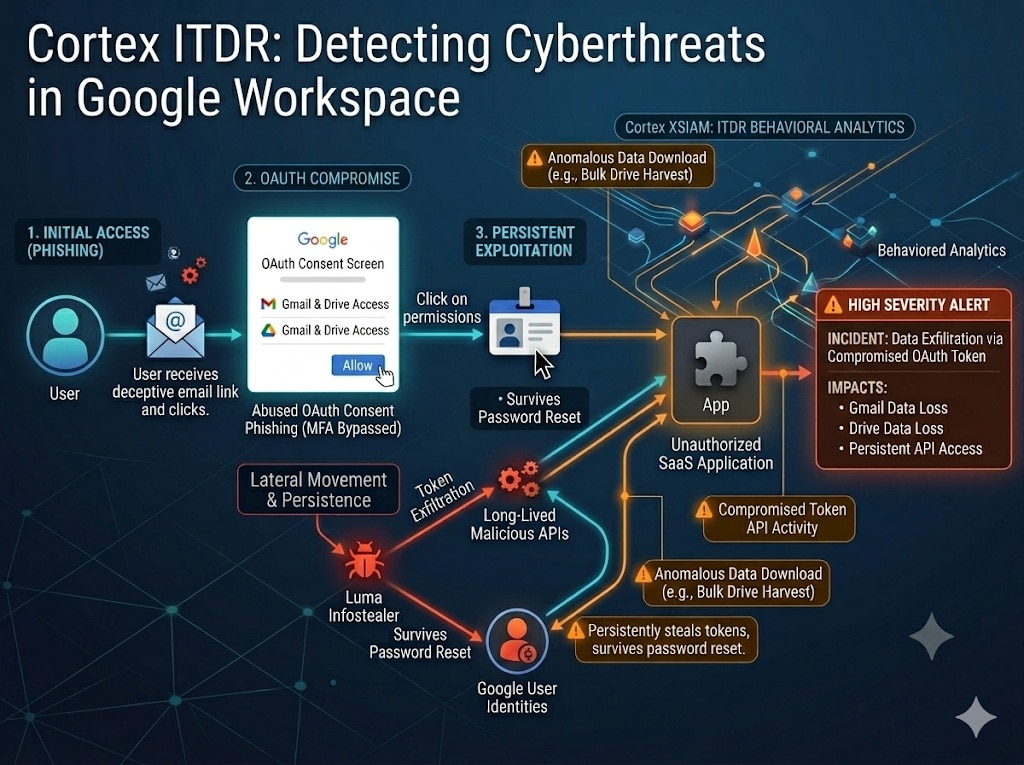
DNS remains one of the most critical and most frequently exploited services in the environment as organizations expand their cloud workloads. Threat a...
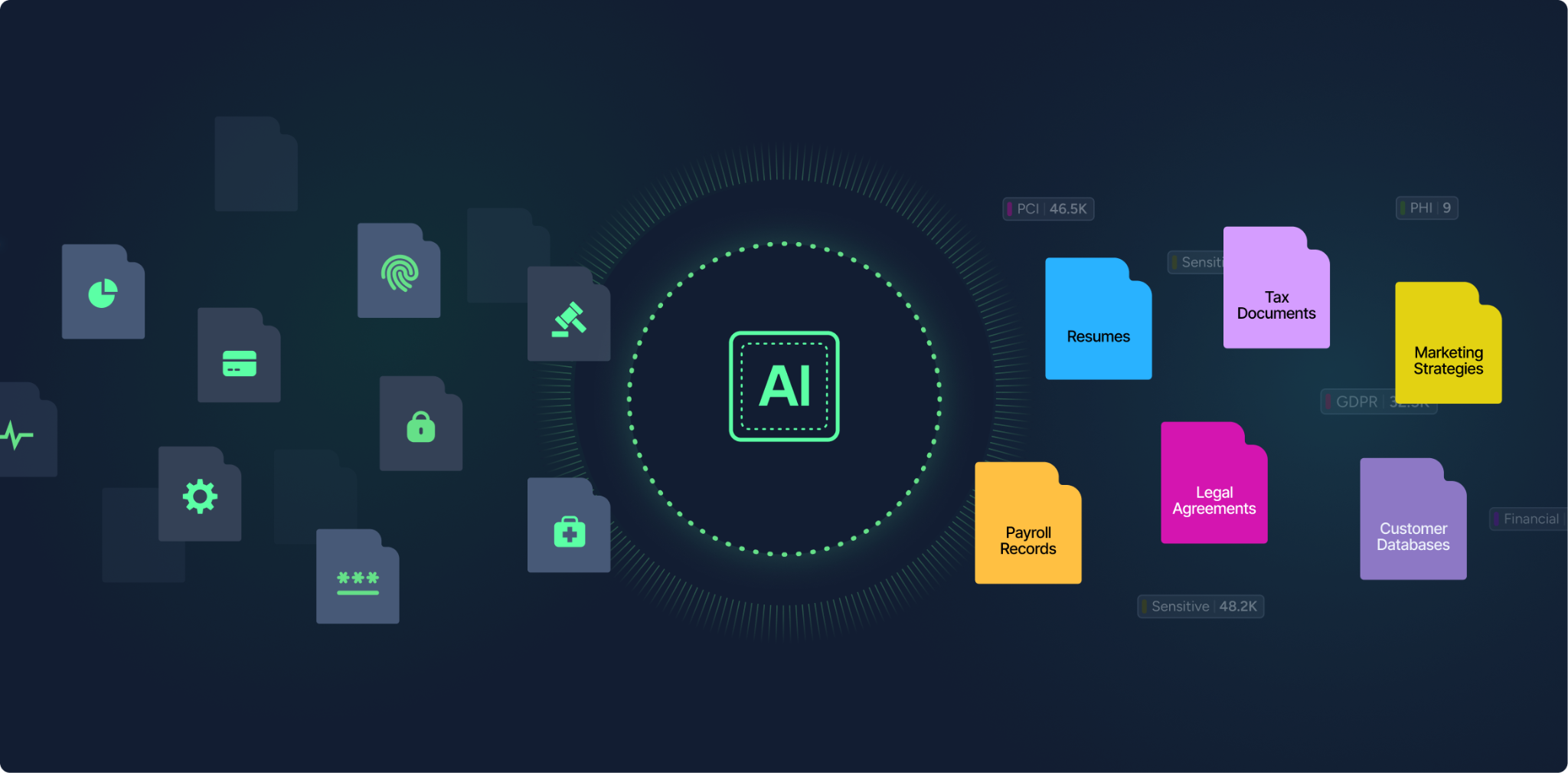
In every company, sensitive data lives in places security teams cannot always see. It’s not encrypted. It’s just out of reach, overlooked, or forgotte...
Palo Alto Networks acquires Portkey, integrating its AI Gateway into Prisma AIRS. Get the unified control plane to securely govern and operationalize ...
In the modern IT environment, an "export" is triggered not only by physical shipment but also by the electronic transmission of controlled data across...
Software supply chain security now requires protecting AI tools, dependencies, pipelines and runtime systems from machine-speed attacks across modern software apps.
The reality of quantum computing is no longer a distant academic theory; it is an impending shift that demands immediate action from cybersecurity lea...
Data classification in the age of AI requires more than regex. Learn how hybrid models balance precision, privacy, scale and cost for trusted data sec...
AI security requires unified visibility across AI assets, data, identities, and runtime activity to help teams find shadow AI and prioritize risk across runtime, too.
Frontier AI security demands cloud protection built for AI agents, hidden data flows, and machine-speed threats across modern multicloud environments for AI systems.
Software supply chain security now requires protecting AI tools, dependencies, pipelines and runtime systems from machine-speed attacks across modern software apps.
Introducing native support for leading frontier AI models, including Claude Sonnet 4.6, Claude Opus 4.8 and Gemini 3.5 Flash across the Cortex platform.
Every morning, SOC analysts log into an environment where visibility feels fragmented, spending hours pivoting between disconnected telemetry feeds and managing noisy alerts that r...
Stop paying the visibility tax. Learn why Palo Alto Networks made data ingestion of enhanced application logs free to help CISOs eliminate blind spots and reduce SOC TCO.
Frontier AI is accelerating cyberattacks, creating complex exploits in hours. Learn why your SOC has six months to adapt and what Cortex's defensive testing reveal
Ever since IMPACT, the energy from the Idira launch has been unstoppable. The customer conversations have not slowed down for a day. The hype is real,...
Introducing Idira: The AI-Driven Identity security platform. Extend Zero Standing Privilege to every human, machine, and AI agent identity in your enterprise.
The viral surge of OpenClaw has captured the tech world’s imagination, turning it into a high-profile example of how quickly autonomous AI agents can move from curiosity to real op...
As artificial intelligence (AI) adoption surges and organisations move from the ‘should we?’ phase to the ‘how do we?’ phase, it’s natural to evaluate the likelihood of positive re...
Secure your AI models. The Nutanix and Palo Alto Networks Prisma AIRS integration provides advanced AI Model Security and AI Red Teaming for a secure-by-design AI pipeline.
A technical analysis of three chained zero-day vulnerabilities in Siemens ROX II OT switches that allow privilege escalation and persistent root access....
A cybercrime campaign combined a loader-as-a-service framework and DLL sideloading via a Go-compiled fake MpClient.dll, a novel evasion layer combination....
Sign up to receive must-read articles, Playbooks of the Week, new feature announcements, and more.
By submitting this form, you agree to our Terms of Use and acknowledge our Privacy Statement. Please look for a confirmation email from us. If you don't receive it in the next 10 minutes, please check your spam folder.