- 1. Why did MLOps emerge in the first place?
- 2. What are the core components of a modern MLOps architecture?
- 3. How does the MLOps lifecycle actually work end-to-end?
- 4. What roles are involved in MLOps?
- 5. What challenges do organizations run into when adopting MLOps?
- 6. Top 7 best practices behind mature MLOps
- 7. How MLOps relates to adjacent disciplines (DevOps, DataOps, ModelOps, LLMOps)
- 8. How MLOps is evolving in the era of LLMs, agents, and retrieval
- 9. MLOps FAQs
Table of contents
- Why did MLOps emerge in the first place?
- What are the core components of a modern MLOps architecture?
- How does the MLOps lifecycle actually work end-to-end?
- What roles are involved in MLOps?
- What challenges do organizations run into when adopting MLOps?
- Top 7 best practices behind mature MLOps
- How MLOps relates to adjacent disciplines (DevOps, DataOps, ModelOps, LLMOps)
- How MLOps is evolving in the era of LLMs, agents, and retrieval
- MLOps FAQs
What Is MLOps? Machine Learning Operations | Starter Guide
5 min. read
Table of contents
- Why did MLOps emerge in the first place?
- What are the core components of a modern MLOps architecture?
- How does the MLOps lifecycle actually work end-to-end?
- What roles are involved in MLOps?
- What challenges do organizations run into when adopting MLOps?
- Top 7 best practices behind mature MLOps
- How MLOps relates to adjacent disciplines (DevOps, DataOps, ModelOps, LLMOps)
- How MLOps is evolving in the era of LLMs, agents, and retrieval
- MLOps FAQs
MLOps is a discipline that unifies machine learning, software engineering, and data engineering to build, deploy, monitor, and maintain ML systems in production.
It manages the lifecycle of data, models, and code as connected workflows. MLOps isn't a toolset. It sits alongside DevOps, DataOps, ModelOps, and LLMOps as a distinct operational practice.
Why did MLOps emerge in the first place?
Organizations have rapidly increased their use of AI and machine learning (ML) as part of everyday software systems.
Adoption grew fast. However, production success didn't. Many teams struggled to run ML systems reliably outside controlled experimentation. Which is why this shift created new expectations for automation, prediction, and decision support.
Basically, the industry could build ML models. But it couldn't operate them well.
More specifically:
ML systems depend on data. And data changes over time. As a result, the model can drift even if the code stays the same. Input patterns shift. Pipelines break. Performance degrades quietly.
Traditional DevOps practices assume stable inputs and deterministic behavior. But ML doesn't follow those assumptions.
Experimental workflows added more challenges.
Data scientists and ML engineers created lots of datasets, features, and model versions. They tuned parameters and retrained often. These steps produced artifacts that needed tracking, reproducibility, and review. And most software workflows weren't designed for this level of variation.
Integration exposed further gaps.
ML platform teams needed aligned environments, clear handoffs, consistent telemetry, and coordinated deployment. Without these, systems failed for operational reasons rather than model quality.
That is what led to the emergence of MLOps. A discipline built to manage data, models, code, environments, and feedback loops as one operational system.
What are the core components of a modern MLOps architecture?
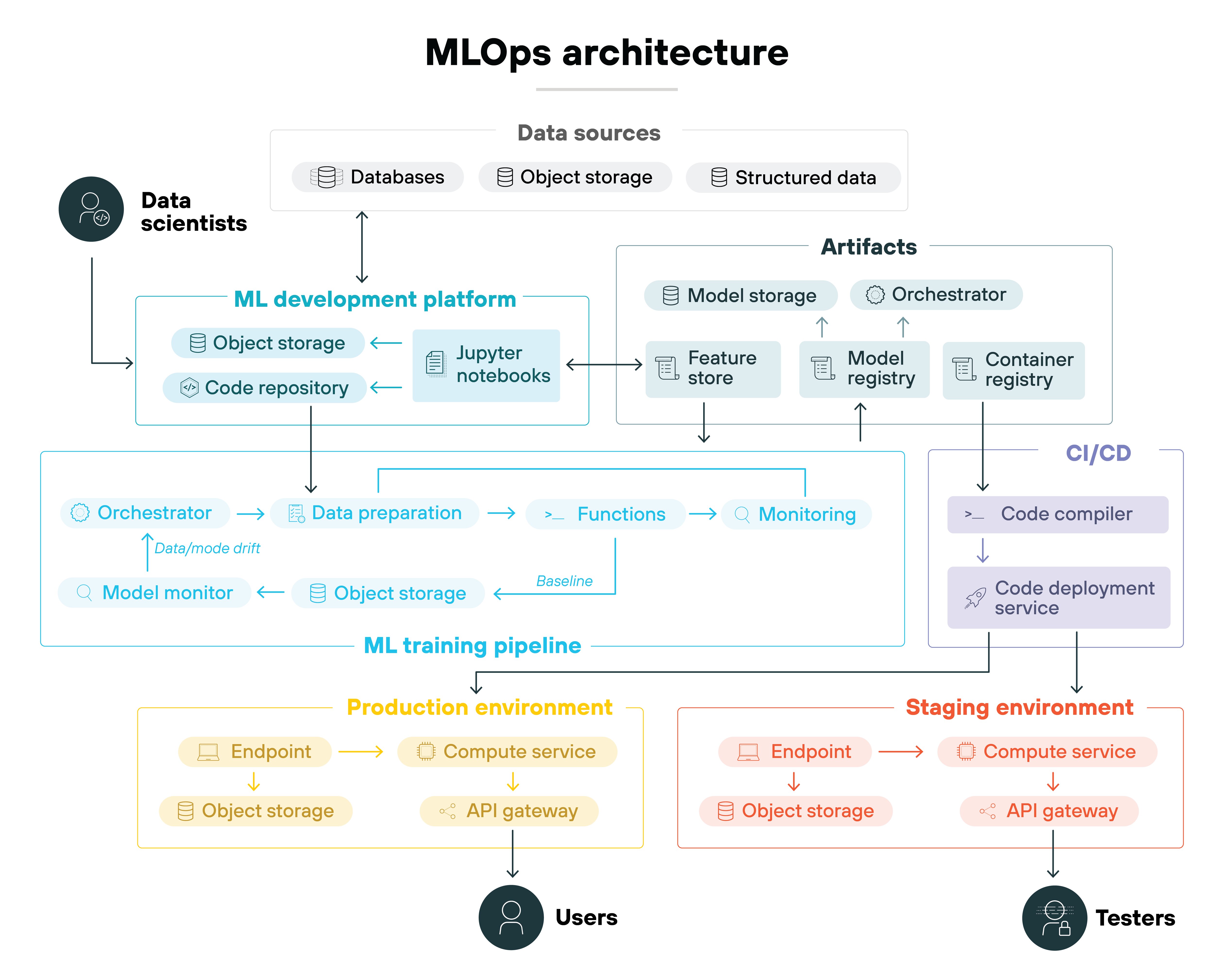
An MLOps architecture works because each component supports a different part of the lifecycle.
The system moves code, data, and models through training, validation, deployment, and monitoring. And each one solves a specific operational problem.
Understanding the architecture starts with understanding the purpose each component serves.
Let's dig into the core components of MLOps architecture:
CI/CD provides the entry point.
It creates a consistent way to package code, pipeline steps, and configuration. It also gives teams a safe way to promote changes through build, test, and deployment. Without this, downstream workflows break before they begin.
Workflow orchestration manages the pipeline itself.
It defines what runs, when it runs, and what each step depends on. It also keeps the process reproducible as data, features, or models evolve. This solves the problem of coordinating multi-step ML workflows.
Feature stores support both experimentation and serving.
They centralize feature definitions and make them available across teams. And they reduce training–serving skew by ensuring feature logic stays consistent in every environment. Which prevents duplicated feature code and inconsistent results.
Metadata stores record the details of each pipeline run.
They track datasets, parameters, artifacts, and outputs. And make lineage and reproducibility possible. That context makes it clear how the model was constructed and why its behavior looks the way it does.
Model registries manage trained models as versioned assets.
They keep track of which model is approved, support promotion from staging to production, and they give teams a structured way to review changes. This keeps model releases controlled and reviewable.
Model serving layers provide the runtime for predictions.
And expose models through real-time or batch interfaces. Also, they standardize how predictions are delivered across environments. That consistency helps keep latency low and behavior reliable. Even under production traffic.
Monitoring watches data, model behavior, and system health.
Monitoring tracks data quality, model performance, and infrastructure status. It detects signs of drift and flags broken pipelines. These signals alert teams when behavior changes or performance drops. Before silent failures impact downstream systems.
Environment and infrastructure management keep training and serving consistent across machines.
They make sure training and serving environments stay aligned as workloads move between systems. This consistency enables reproducible results. It also allows the system to scale reliably as demands grow. Without introducing drift between development and production.
Feedback loops close the lifecycle.
They connect monitoring back to development. They trigger retraining. And they help teams keep models aligned with changing data.
Together, these components create the architecture that makes ML operational.
How does the MLOps lifecycle actually work end-to-end?
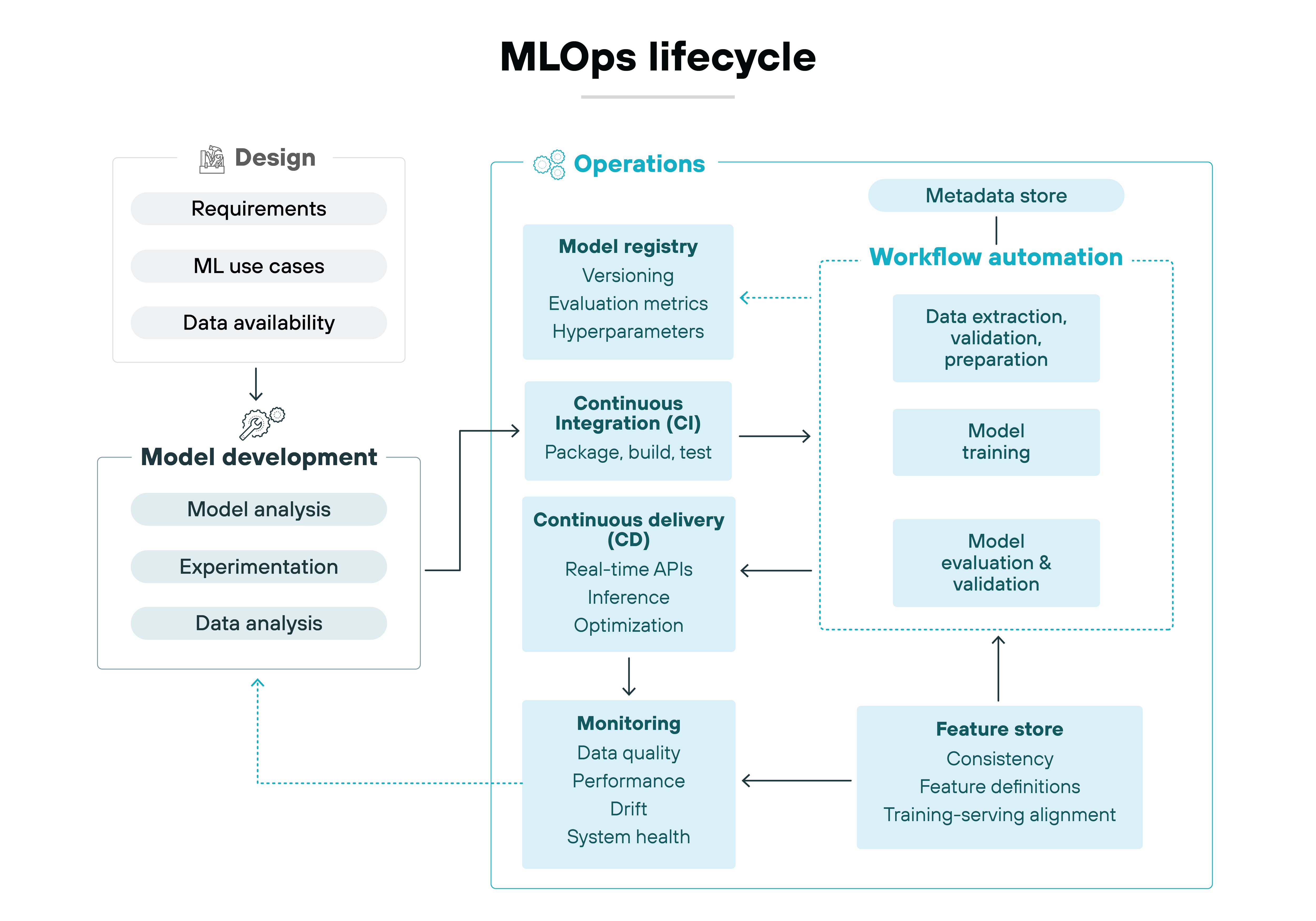
An ML system moves through a lifecycle that connects its development, deployment, and long-term operation.
Each phase prepares the next. Together, these phases function as one loop rather than a one-way pipeline.
Let's break down each phase of the MLOps lifecycle:
-
Project initiation
The lifecycle begins by defining the problem ML is meant to solve.
This includes the model's purpose, the expected inputs, and the operational constraints. It also includes early decisions about how performance will be evaluated and monitored.
These choices shape every downstream step.
Note:This phase may involve cross-functional input from business, product, and data teams. Especially when operational constraints are still fluid. -
Data preparation
Work then shifts to the data that will support the model.
Data must be located, profiled, cleaned, and labeled. Distribution changes, quality gaps, and validation needs are identified.
This prepares the ground for reproducible features and consistent training.
-
Feature engineering
The raw data is transformed into features the model can learn from.
Rules for cleaning, aggregating, and deriving attributes are created and refined. These rules must work both during experimentation and in production.
The objective is to align training and serving.
Note:In many organizations, the same team doesn't own both feature creation and feature serving, making alignment across environments more difficult in practice. -
Experimentation and training
Next comes experimentation.
Different algorithms, parameters, and configurations are tested. Each training run produces artifacts and results that must be tracked.
The goal is to identify the version of the model that performs best under the defined conditions.
-
Model validation
The selected model is then validated.
It's tested on unseen data. It's checked for regressions. And it's reviewed against the success criteria defined in the initiation phase.
This ensures the model is ready for controlled deployment.
Note:Validation criteria are often negotiated or reinterpreted late in the process, especially if early baselines were unrealistic or poorly defined. -
Deployment
The model is packaged with its serving logic.
It moves through staging. Automated checks run. Environments must be consistent so the model behaves the same way it did during validation.
Deployment is where the system becomes operational.
-
Monitoring
Once live, the system must be monitored.
Data quality, model behavior, and serving performance are tracked. Drift is detected. Pipeline issues surface.
Monitoring provides the signals that show when intervention is needed.
-
Feedback and retraining
These signals initiate feedback loops.
New data is incorporated. Features are updated. Models are retrained and evaluated. Improved versions move back toward deployment.
It's how the lifecycle maintains alignment with changing conditions.
Note:Feedback loops don't always restart at data prep. Many begin midstream with new features, updated parameters, or model refinement only.
The lifecycle works because each phase strengthens the next. And the entire loop keeps ML systems reliable as their environment changes.
What roles are involved in MLOps?

MLOps brings together several disciplines.
Each one supports a different part of the lifecycle. The value comes from how these responsibilities work together.
Data engineers shape the data layer.
Their work defines how information enters the system. It also determines how stable training and serving will be long term. When this foundation is solid, the entire workflow benefits.
Data scientists explore the problem space and develop candidate models.
They experiment to reveal what the system can learn. Form ideas. And set the initial direction of the model.
ML engineers turn those ideas into production-ready components.
This process is all about connecting models with serving logic. It also prepares the system to operate under real conditions. In practice, this is where experimentation transitions into applied use.
MLOps engineers maintain the workflows that hold the lifecycle together.
The role is all about operating orchestration, CI/CD, monitoring, and retraining. It ensures the system continues to function as one loop instead of disconnected steps.
Platform engineers support the shared environment beneath the workflow.
They maintain tooling, infrastructure, metadata systems, and storage. Which provides the consistency the lifecycle needs to operate smoothly.
Governance and quality roles provide oversight.
Oversight related work is focused on reviewing lineage, documentation, and model behavior to ensure the system meets organizational expectations before and after deployment.
Now that we've broken down who's responsible for what in MLOps, let's get into the challenges they face in the adoption process.
What challenges do organizations run into when adopting MLOps?

Adopting MLOps tends to surface challenges that don't appear in traditional software work.
These challenges crop up because ML systems depend on data, experiments, and cross-team coordination. Which means organizations have to adjust both their technical workflows and their team structures.
Socio-technical challenges appear first.
Teams often work in silos. They use different tools. They use different vocabulary. And they approach problems from different angles.
This slows down collaboration. It also makes ownership unclear.
Pipeline fragility shows up next.
ML pipelines break when data shifts, schemas change, or upstream systems behave unpredictably. And these failures can be difficult to diagnose because they occur across multiple components and roles.
Continual learning adds more pressure.
Retraining is required when data changes. Evaluation is needed to confirm behavior. Rollout must be controlled. And monitoring must catch regressions early.
A lot of organizations aren't prepared to automate these cycles.
Platform complexity increases the difficulty.
ML systems rely on orchestrators, feature stores, metadata stores, registries, and serving layers.
Each component has its own behavior and failure modes. And each one introduces a new operational boundary.
Moving to MLOps platforms can also introduce migration challenges.
Organizations have to shift from manual workflows to automated ones. And align environments.
Not to mention, there's the task of making legacy systems compatible with new components.
Automation boundaries create the final challenge.
At the same time, not every step should be automated. Some require review. Some require safety checks.
MLOps teams have to tackle determining where automation helps and where human oversight is needed.
MLOps isn't a tooling exercise. It's a shift in how ML systems are built, operated, and maintained. Organizations succeed when they approach it as an engineering discipline with clear ownership, defined workflows, and a lifecycle that can adapt to changing data.
Top 7 best practices behind mature MLOps

Operating ML systems at scale requires structure. The lifecycle moves quickly, and small issues in one phase can ripple into others.
These best practices help you keep the system predictable, reproducible, and easier to operate as data and conditions evolve:
Establish transparent lineage
Track how data, features, and models move through the lifecycle. Record the origin of every artifact and how it changed over time.
Use that lineage to trace issues back to their source instead of troubleshooting blindly. Make it available to everyone involved so decisions are based on shared context.
And rely on it to support reproducibility, governance, and responsible deployment.
Tip:Use unique artifact IDs, not file paths. They remain stable across reids or moves, making lineage tracking consistent across versions and environments.Enforce reproducibility
Capture the parameters, configurations, and environment details used in every experiment or pipeline run. Recreate those runs to confirm that results are consistent and not dependent on hidden variation.
Use reproducibility to compare models fairly and understand performance differences. Apply it throughout the lifecycle so workflows behave predictably.
Important: reproducibility should be the basis for trustworthy evaluation.
Tip:Pin library and dependency versions. Locking environments prevents subtle changes from newer packages and ensures experiments run consistently.Validate quality at every stage
Check data, features, and models before they move downstream. Confirm that inputs meet expectations before training begins.
Review model output for regressions before deployment. Use automated tests to surface issues early rather than after the system breaks.
Always treat these checks as safeguards that reduce the risk of shipping degraded behavior.
Tip:Use thresholds to auto-reject flawed data or models. Block inputs with issues like nulls, leakage, or poor accuracy before they move downstream.Monitor the system continuously
Observe data patterns, model behavior, and pipeline health once the system is live. Detect drift as input distributions or model outputs start to shift. Identify failing pipelines early so their impact is limited.
Use monitoring to understand when the model no longer reflects current conditions.
These signals should guide investigation, retraining, or deeper evaluation.
Tip:Alert on both fast spikes and slow drifts. Catch sudden failures and gradual decay early by monitoring for both patterns.Automate lifecycle workflows
Replace manual steps with orchestrated workflows for training, validation, and deployment. Standardize how work runs so results are consistent and easier to manage.
Reduce human error by letting the system handle repetitive tasks. Use automation to free up time for higher-value improvements and keep the lifecycle moving without interruption.
Govern artifacts as controlled assets
Version datasets, features, models, and metadata so their evolution is clear. Use approval flows to review changes before they affect production.
Capture the intent behind each update through documentation. Ensure that artifacts enter and move through the lifecycle with accountability.
And maintain control so you always know what's running and why.
Centralize platform capabilities
Consolidate shared MLOps functions into unified environments for training, serving, storage, and metadata.
Standardize the tooling that teams use so workflows behave the same across different stages. Provide consistent infrastructure that reduces operational friction. Use platformization to simplify onboarding and coordination.
Platformization also creates a shared foundation that makes collaboration easier across roles.
How MLOps relates to adjacent disciplines (DevOps, DataOps, ModelOps, LLMOps)
MLOps doesn't exist in isolation.
It sits next to other operational disciplines that shape how software and data move through an organization. Each one handles a different part of the workflow.
Understanding those differences helps clarify what MLOps is responsible for—and what it isn't.
Here's a comparison between MLOps and related disciplines:
| Discipline | What it focuses on | How it relates to MLOps |
|---|---|---|
| DevOps | Software delivery and operational automation | MLOps builds on DevOps but adds data, experiments, and model lifecycle needs |
| DataOps | Data pipelines, data quality, and data reliability | MLOps relies on DataOps because models depend on stable, well-managed data |
| ModelOps | Governance and oversight of models after deployment | MLOps overlaps with ModelOps but covers the full ML lifecycle, not only post-deployment control |
| LLMOps | Operating large language models, RAG workflows, and evaluation loops | MLOps provides the foundation; LLMOps extends it for prompt behavior, embeddings, and retrieval consistency |
A key detail: These disciplines have to work together. ML systems depend on data, software, and governance workflows.
The result is a shared operating environment where each discipline owns part of the system. MLOps fits by connecting these parts through processes that manage data, models, code, and feedback loops as one lifecycle.
How MLOps is evolving in the era of LLMs, agents, and retrieval
LLMs changed how organizations build and operate ML systems.
They introduced new behaviors, new sources of drift, and new evaluation needs. Which means the core ideas behind MLOps still apply. But the way teams use those ideas must adapt.
In other words: LLMOps isn't separate from MLOps. It's an extension of it.
In practical terms:
LLMs depend on prompt patterns, embeddings, and retrieval systems. This creates new drift types.
Prompt drift appears when small wording changes alter model behavior. Embedding drift appears when vector representations shift as data changes. Retrieval drift appears when search results become inconsistent. And these changes require new monitoring signals and new ways to detect regressions.
Evaluation also changes. Simple accuracy metrics are no longer enough.
Evaluation pipelines must review output quality, factuality, and stability. These pipelines also need to run continuously because LLM outputs can vary even without code or model updates.
Then there's the fact that LLMs introduce agent workflows, which increases operational risk.
Agents take actions, chain model calls, and rely on external tools. Which means there's an increased need for guardrails. Controlled orchestration, human oversight, and review cycles help keep agent behavior predictable.
Feedback loops expand as well.
Ranking, scoring, and structured feedback become part of the evaluation process. Reinforcement signals help improve outputs. And retrieval adjustments keep the system aligned with changing data.
MLOps evolves by absorbing these needs. And by extending its lifecycle, monitoring, and governance practices to support modern AI systems.
RESEARCH REPORT: THE STATE OF GENERATIVE AI 2025
Get new data on GenAI adoption and usage, drawing on observations of 7K+ enterprises.
Download report
MLOps FAQs
MLOps is the discipline that manages the end-to-end lifecycle of machine learning systems. It unifies data engineering, software engineering, and ML engineering to build, deploy, monitor, and maintain models as reliable, reproducible, and continuously improving production systems.
DevOps focuses on software delivery and operational automation. MLOps builds on DevOps but adds data, experimentation, lineage, drift monitoring, model validation, and retraining workflows. It manages the behavior of ML systems over time, not just code and infrastructure.
MLOps governs how machine learning systems are built and operated. AIOps applies AI to improve IT operations such as monitoring, alerting, and incident response. MLOps manages ML lifecycles. AIOps uses ML inside operational tooling. They serve different purposes.
MLOps can be challenging because it spans multiple domains. It requires understanding data workflows, experimentation, validation, deployment, monitoring, and retraining. It also requires coordinating roles and managing system complexity. The difficulty comes from the breadth of responsibilities, not from any single task.
The four commonly referenced categories are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. These categories describe how models learn from data and how feedback is used during training.