- 1. How to actually secure data in practice
- 2. 1. Classify data by sensitivity, not just type
- 3. 2. Enforce least privilege with contextual access control
- 4. 3. Prevent unauthorized flows using information flow control
- 5. 4. Secure data at rest using encryption and isolation
- 6. 5. Protect data in transit with strong, authenticated protocols
- 7. 6. Minimize data exposure in non-production environments
- 8. 7. Limit data retention and enforce secure deletion
- 9. 8. Harden systems to prevent indirect data compromise
- 10. 9. Detect data misuse through audit trails and behavioral signals
- 11. 10. Design for resilience through redundancy and verifiable integrity
- 12. 11. Protect against inference and aggregation attacks
- 13. 12. Integrate data security into system design from the start
- 14. How to use frameworks to support data security best practices
- 15. Data security best practices FAQs
Table of contents
- How to actually secure data in practice
- 1. Classify data by sensitivity, not just type
- 2. Enforce least privilege with contextual access control
- 3. Prevent unauthorized flows using information flow control
- 4. Secure data at rest using encryption and isolation
- 5. Protect data in transit with strong, authenticated protocols
- 6. Minimize data exposure in non-production environments
- 7. Limit data retention and enforce secure deletion
- 8. Harden systems to prevent indirect data compromise
- 9. Detect data misuse through audit trails and behavioral signals
- 10. Design for resilience through redundancy and verifiable integrity
- 11. Protect against inference and aggregation attacks
- 12. Integrate data security into system design from the start
- How to use frameworks to support data security best practices
- Data security best practices FAQs
Top 12 Data Security Best Practices
7 min. read
Table of contents
- How to actually secure data in practice
- 1. Classify data by sensitivity, not just type
- 2. Enforce least privilege with contextual access control
- 3. Prevent unauthorized flows using information flow control
- 4. Secure data at rest using encryption and isolation
- 5. Protect data in transit with strong, authenticated protocols
- 6. Minimize data exposure in non-production environments
- 7. Limit data retention and enforce secure deletion
- 8. Harden systems to prevent indirect data compromise
- 9. Detect data misuse through audit trails and behavioral signals
- 10. Design for resilience through redundancy and verifiable integrity
- 11. Protect against inference and aggregation attacks
- 12. Integrate data security into system design from the start
- How to use frameworks to support data security best practices
- Data security best practices FAQs
The primary data security best practices include:
- Classify data by sensitivity
- Enforce least privilege
- Prevent unauthorized flows
- Secure data at rest
- Protect data in transit
- Minimize data exposure
- Limit data retention
- Harden systems
- Detect data misuse
- Design for resilience
- Protect against inference/aggregation attacks
- Integrate data security into system design
How to actually secure data in practice
Most discussions about common data security best practices focus on surface-level controls: encrypt your data, turn on MFA, run backups.
Sure, these are important. But they don't explain why data breaches still happen in environments that follow all those steps.
Here's the thing:
The real risk isn't just a missing control. It's weak architecture. It's misplaced trust. It's assuming systems behave correctly when they fail.
Basically, effective data security isn't about which tools you deploy. It's about how you design and manage the systems that store, process, and protect your data.
The sections that follow go deeper than checklists. They walk through 12 real-world data security best practices that focus on the system level—where most breaches actually begin.
1. Classify data by sensitivity, not just type
The principle here is simple: not all data is created equal. But many organizations still treat it that way.
Instead of just labeling data by format—like documents, spreadsheets, or emails—you need to classify based on how damaging it would be if that data were exposed, altered, or lost. This includes factors like confidentiality, integrity, and regulatory sensitivity.
Why does that matter?
Because data type tells you almost nothing about its risk. A log file and a payroll record might both be text files. But one can reveal credentials, the other PII.
Data classification by sensitivity helps you understand which data needs stronger controls, tighter access, or even additional monitoring. It's also a requirement baked into most formal models for data security, including multilevel security.
Practically, this means defining your classification labels based on risk—e.g., public, internal, confidential, restricted—and enforcing them across systems.
Like this:

Classification should influence how data is stored, encrypted, shared, and deleted. And it's not about compliance labels. It's about operational control.
Example:
An organization classifies customer financial data as “restricted.” As a result, data loss prevention (DLP) rules block users from emailing it externally, and cloud storage systems reject uploads to non-approved destinations. These controls activate based on the label—not just the file type.
| Further reading: What Is Data Classification?
2. Enforce least privilege with contextual access control
Only give users and systems access to the data they actually need—nothing more. That's what least privilege means.
But to apply it effectively, you also need to consider context. This includes factors like user roles, device posture, time of day, and data sensitivity.
This is what that looks like at a high level:

Why?
Because static permissions alone aren't enough. A user might be authorized to access a system, but that doesn't mean they should access it from an unmanaged device or at 2 a.m. from a different country.
Without context, enforcement lacks precision. That's how excessive access rights, stale accounts, and edge cases lead to data exposure.
In real-world scenarios, adopting zero trust principles that enforce least privilege with context means applying access policies that adapt.
This could involve role-based access control (RBAC) combined with conditional logic. Like restricting access based on geography, session risk, or sensitivity level.
Example:
A developer might have access to production data only during approved change windows from managed devices. Outside of those conditions, access should be automatically blocked or escalated for review.
| Further reading:
3. Prevent unauthorized flows using information flow control
Information flow control focuses on stopping sensitive data from leaking into places it shouldn't—whether intentionally or not. That includes unauthorized access, but also indirect exposure through things like shared memory, timing behavior, or exception handling.
These are known as information flows. And unless they're controlled, even properly labeled and restricted data can be compromised.
Why does that happen?
Because access control alone only governs who can read or write data—not how that data might move between systems or influence outputs.
That's where information flow control comes in.
It tracks how data propagates through a system and ensures that low-trust entities can't observe or be influenced by high-trust inputs. Models like noninterference and multilevel security are designed around this concept.
 to unknown destinations, including an app server and database server, with a note that 'unknown data flows increase risk.' The flows include multiple red lines going to and from labeled components such as IDP, users, app server, and a business partner via VPN, but some arrows terminate at 'Unknown' with no destination. On the right, labeled 'Mapped data flows' in green, cleanly labeled arrows show documented, traceable paths for different types of data—such as 'HR data,' 'Invoices & contracts,' and 'Financial, supply chain, & sales data'—flowing from the IDP through the app server, file server, and database server, including secure connections to a business partner. Labels such as 'Identity & authorization' and 'ERP system' help differentiate data types and endpoints. Both diagrams are encased in data center boxes with consistent components, but the right side illustrates full monitoring and control.")
Operationally, this means applying security controls that account for data dependencies, shared resources, and covert channels.
Example:
If a variable labeled “confidential” affects a public-facing output—even through overflow behavior or timing—then sensitive information is leaking. Systems that process mixed-sensitivity data, like healthcare or intelligence platforms, often rely on static analysis, sandboxing, or OS-level enforcement to control those flows. Without that, data leakage can happen invisibly, even when access control policies are followed exactly.
4. Secure data at rest using encryption and isolation
This principle is about protecting stored data so it remains confidential and tamper-resistant, even if the system is breached. Encryption helps ensure that the data can't be read. Isolation helps ensure that unauthorized systems or users can't reach it in the first place.
Why do both matter?
Because encryption alone doesn't control access. And isolation alone doesn't make the data unintelligible. Together, they reduce the risk of compromise from both direct attacks and lateral movement.
 on buckets/disks,' 'Manage encryption keys separately from data (HSM/KMS),' and 'Data encrypted at rest' with a sub-note listing 'Customer PII, configs, logs, etc.' Each step shows progressive protection measures that isolate, restrict, and encrypt stored data.")
In practice, this often means encrypting data at rest using strong algorithms such as AES-256, with well-managed keys stored separately from the data.
Isolation could mean enforcing strict segmentation between production and test environments, or restricting backup access to dedicated administrative paths.
Example:
Even if an attacker gains access to a virtual machine snapshot, properly encrypted and segmented storage helps prevent data exposure. Without both measures, attackers can bypass one layer entirely.
| Further reading: What Is Data Encryption?
5. Protect data in transit with strong, authenticated protocols
When data moves between systems, it's at greater risk of being intercepted, altered, or spoofed. Protecting data in transit means using protocols that provide both encryption and authentication. That way, the data stays confidential, and the recipient knows it came from a trusted source.
Why both?
Because encryption alone isn't enough.
If a connection isn't authenticated, an attacker could impersonate a trusted system. And if data is authenticated but not encrypted, the contents could still be exposed. Protecting data in transit requires safeguards for both confidentiality and integrity.
This typically involves enforcing the use of TLS with modern cipher suites, verifying certificates, and blocking insecure protocols like plain HTTPoutdated VPN tunnels.
,' shows a blue bidirectional arrow labeled 'Encrypted data' between the client and server, each marked with a certificate icon; an annotation reads 'Attacker can: impersonate.' The bottom tier, labeled 'With Encryption & Authentication (mTLS),' shows green arrows between the client and server, each again marked with certificate icons, and a central label reading 'Encrypted data'; an annotation reads 'Attacker can: do nothing.'")
Example:
Many organizations configure mutual TLS (mTLS) between services to ensure both endpoints are verified. That way, even if the network is compromised, attackers can't silently redirect or tamper with sensitive data in motion.
6. Minimize data exposure in non-production environments
Development, testing, and QA environments are often overlooked when it comes to data protection. But they can still hold copies of real production data. Sometimes with fewer controls. And that makes them a frequent weak spot for exposure.
Here's why that's an issue.
Non-production systems aren’t always monitored or locked down. They may have broader access, outdated software, or looser segmentation. So regardless of whether production is secure, attackers often target these environments to get in through the back door.
The fix is simple in concept. Don't use real sensitive data in non-production environments unless it's absolutely necessary. And if you do, use strong masking or tokenization to neutralize the risk.
,' which points to both the secure environment and back to the configuration icon. The 'Secure environment' includes three components connected by arrows: 'Backup of production' depicted as a monitor, 'Secure non-production database' represented by a database icon, and 'Automated masking using command line' with a gear symbol. From the secure non-production database, a downward arrow points to 'Masked backup' represented by a storage icon. A final arrow flows from the masked backup into the red-dotted 'Dev environment,' which contains icons for a desktop, laptop, printer, person, and server, indicating various development and test systems.")
Example:
Replacing customer names and payment details with dummy values still lets developers test workflows without the liability of real data leaks. It's one of the easiest ways to cut down your attack surface.
7. Limit data retention and enforce secure deletion
Data that's no longer needed doesn't just take up space. It becomes a liability. The longer it's retained, the more opportunities exist for unauthorized access, regulatory violations, or exposure in an incident.
This is what winds up happening.
High-risk data often outlives its operational use. Without a defined retention schedule or clear lifecycle policies, old data lingers—and systems and people forget it’s even there. That leads to overlooked risks and makes compliance harder to prove.
The answer is to treat data deletion as a deliberate security process.
This involves enforcing lifecycle rules for retention and disposal. And applying secure deletion techniques—also called media sanitization—when data is no longer required.
Example:
Securely overwriting decommissioned disk sectors or wiping cloud snapshots ensures that data isn't recoverable later. It's one of the few ways to guarantee that sensitive information stays gone.
8. Harden systems to prevent indirect data compromise
Even when data is properly encrypted and access controls are in place, attackers can still get to it indirectly. That includes exploiting software flaws, abusing misconfigurations, or using dependency vulnerabilities to move laterally and reach protected data.
This matters because many breaches don't result from a direct hit on a database. Instead, attackers find their way in through a weak service, a forgotten admin panel, or an outdated library.
Once inside, they escalate privileges, pivot across the environment, and harvest data they were never supposed to reach.
Here's what to do: Treat system hardening as part of your data security strategy.

That means applying patches promptly, scanning for misconfigurations, locking down default settings, and validating dependencies.
Example:
A data breach could start with a vulnerable web plugin that grants shell access, ultimately exposing files that were otherwise protected. Hardening closes off those paths before they become liabilities.
9. Detect data misuse through audit trails and behavioral signals
Audit logs are useful. But on their own, they're not enough. To catch signs of data misuse, you also need behavioral analysis. Something that goes beyond static logging and checks for unusual activity.
That’s important because:
Not all misuse is loud or obvious. Attackers might access sensitive files using valid credentials. Or an insider might extract data during off-hours from a system they routinely use.
NIST SP 800-53 emphasizes that audit records must be analyzed in context—not just collected. This includes using user behavior analytics and risk scoring to detect misuse, especially when valid credentials are used improperly. By combining access logs with identity attributes and session patterns, organizations can identify threats that bypass traditional controls.
These patterns are hard to detect unless you're actively correlating logs and tracking behavioral signals like access frequency, volume, or movement across systems.
Functionally, this means establishing logging at every control point, then analyze those logs with context. That includes identity context, access time, and behavior baselines.
Tip:
Use risk scoring to prioritize investigation. Combine behavioral signals—like unusual data movement or rare file access—with user attributes and session metadata. That way, your alerts reflect actual risk, not just policy violations.
Example:
If a user in finance suddenly pulls large volumes of engineering IP at 3 a.m., that should still trigger investigation. Access might be permitted, but the behavior is suspicious. That kind of misuse is easier to catch when logs aren’t just stored but scrutinized.
10. Design for resilience through redundancy and verifiable integrity
Securing data is not enough. You also need to ensure it stays accurate, accessible, and usable after disruptions.
That's where resilience comes in. It's about making sure your systems can withstand failures. And your data can recover without loss or corruption.
But here’s the catch.
Even a fully encrypted, well-segmented system can fall short if it lacks integrity checks or backup redundancy. Systems can crash. Data can be overwritten. Infrastructure can fail. And attackers don't always steal data—they sometimes destroy it.
So data availability and trustworthiness must be baked into the design from the beginning.
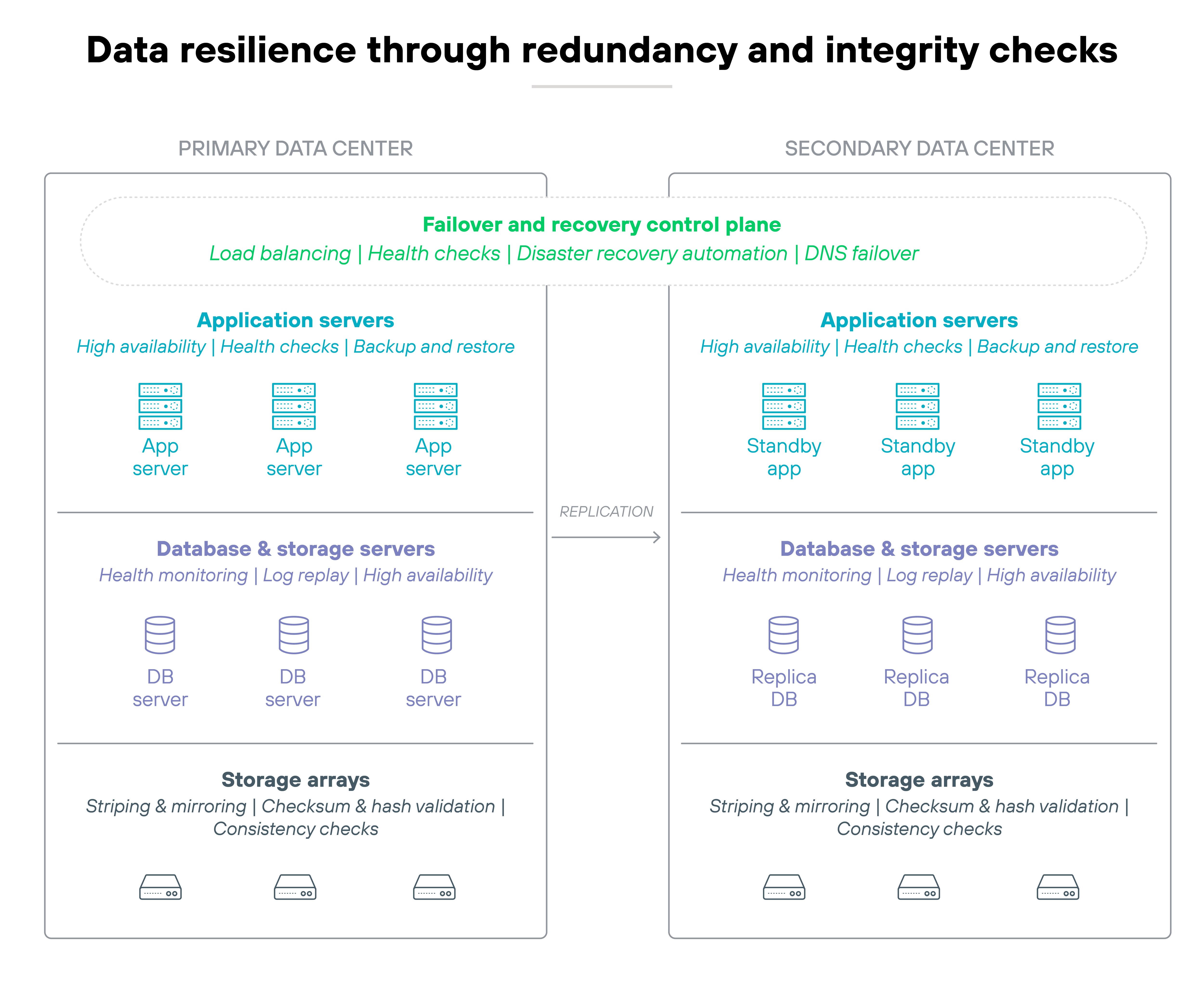
That requires more than just backups. You’ll need tested recovery processes, replicated data stores, and integrity verification mechanisms like checksums and cryptographic hashes. Systems should fail gracefully and validate data as part of routine operation.
Also: Resilience should be combined with business continuity or disaster recovery planning. And regularly tested and measured against recovery time objective (RTO)/recovery point objective (RPO) metrics.
Example:
An organization that uses distributed storage with automatic failover and routine integrity checks is more likely to recover cleanly after a ransomware attack. It can restore data quickly, confirm nothing was tampered with, and resume operations with confidence. That's resilience. And it's just as important as preventing the breach in the first place.
11. Protect against inference and aggregation attacks
Some attacks don’t need direct access to confidential data. They infer it. Or reconstruct it. That’s the risk behind inference and aggregation attacks: Where an adversary gains access to seemingly low-risk data, then combines or analyzes it to uncover restricted information.
Now this is where it gets tricky.
Traditional access controls don't always stop that.
According to NIST SP 800-53, it's not enough to block access to sensitive data—you also need safeguards that prevent users from piecing it together indirectly. Techniques like query restrictions, noise injection, and multilevel enforcement help prevent attackers from reconstructing protected information from low-risk data.
A user may not have permission to view sensitive records directly, but they might be able to query aggregate totals, access metadata, or exploit timing and output patterns. Over time, this can allow attackers—or even legitimate users—to piece together sensitive facts from permitted interactions.
To protect against this, systems need more than role-based access.
You may need multilevel security models, query restrictions, and runtime safeguards like differential privacy or noise injection.
Hybrid enforcement—at both the application and infrastructure layers—can also help.
Tip:
When reviewing access logs, don't just look at what users accessed. Look at patterns in how they accessed it. Repeated queries for slightly different data slices or unusually structured searches can indicate inference attempts. These usage patterns are often early signs of data reconstruction behavior.
Example:
A data analytics platform might limit query frequency and mask high-risk outputs when results are statistically unique. Without these safeguards, environments designed for insight can quickly become exposure risks.
12. Integrate data security into system design from the start
Security decisions made early in a system's lifecycle have long-lasting effects. That's why data protection needs to be built into the architecture. Not added on after deployment.
From data classification to access controls, security principles should shape design requirements and engineering decisions.
NIST CSWP 29 advises that data protections shouldn’t be tacked on later—they need to be integrated into identity systems, analytics platforms, and logging infrastructure from the start. That early alignment makes it easier to protect sensitive data across the full system lifecycle and reduces the risk of architectural blind spots.
The reason?
Retroactively securing a system often leaves gaps. Important protections may be missing, or they may be incompatible with the way the system was built. And since data is usually processed across multiple layers, piecemeal fixes introduce complexity and cost.
When data security is integrated from the start, it aligns with system behavior and business workflows. That reduces risk and makes compliance easier to maintain.
That’s why it’s critical to involve security architects during the design phase. It also means making data protection part of the functional and technical requirements—not just a compliance checklist.
Tip:
Don't wait for system design to “stabilize” before involving security. Engage early enough to influence data models, API structure, and privilege boundaries—before assumptions about trust and access are baked into the architecture.
Example:
When designing a data analytics platform, teams should consider how data labeling, encryption, access policies, and inference protections will work across components from the beginning. Otherwise, patching them in later could require major rework or leave exposures in place.
How to use frameworks to support data security best practices
You don't need to invent your strategy from the ground up.
Widely adopted cybersecurity frameworks already provide strong foundations for securing data. They help translate data security best practices into operational controls and give you a structured way to assess and improve your security posture.
These frameworks support three key goals:
- Protect data across its full lifecycle
- Ensure consistency in policy and control implementation
- Align with industry and regulatory expectations
The following frameworks illustrate how these goals can be put into action:
| Standards and frameworks that support data security best practices | ||
|---|---|---|
| Standard or framework | What it is | How to use it in data security planning |
| NIST Cybersecurity Framework (CSF) | A high-level framework for managing cybersecurity risk | Use it to define categories and subcategories for protecting data (e.g., PR.DS) and map your controls to recognized best practices |
| NIST SP 800-53 Rev. 5 | A catalog of security and privacy controls | Apply specific data-focused controls like SC-12 (cryptographic protection), SC-28 (data confidentiality), and AC-6 (least privilege) to operationalize each best practice |
| NIST SP 800-171 | Security requirements for protecting controlled unclassified information (CUI) | Use it to build access, encryption, and audit policies for sensitive internal or regulated data |
| ISO/IEC 27001 & 27002 | International standards for information security management systems | Use them to define your governance structure, identify data protection objectives, and enforce technical and procedural safeguards |
| CIS Critical Security Controls | A prioritized list of security actions for defense | Reference controls like Control 3 (data protection) and Control 6 (access control) for implementation guidance |
| Cloud Security Alliance (CSA) CCM | A cloud-specific control framework for security and compliance | Use it to align data protection practices across cloud workloads and SaaS applications |
Confidently choose the right data loss prevention solution for your organization, featuring the Gartner 2025 Market Guide for Data Loss Prevention.
DownloadData security best practices FAQs
Examples include classifying data by sensitivity, enforcing least privilege access, securing data in transit and at rest, limiting data retention, and detecting misuse through logging and behavior analysis.
To secure sensitive cloud data, use encryption, enforce access control policies, isolate workloads, and monitor for misuse. It’s also important to limit exposure in non-production environments and integrate security into your architecture from the start.
Classify data by sensitivity, enforce least privilege, control information flows, secure data in transit and at rest, minimize non-production exposure, limit retention, harden systems, detect misuse, design for resilience, guard against inference, and integrate security into system design from the start.
The five pillars of data security are confidentiality, integrity, availability, accountability, and non-repudiation. These principles are supported by mechanisms like encryption, access controls, activity monitoring, and resilient system design.
The four A's of data security are authentication, authorization, auditing, and accountability. These are enforced through methods like contextual access control, activity logging, and role-based policy enforcement.
- Enforce least privilege
- Prevent unauthorized information flow
- Secure data at rest and in transit
- Design for resilience
- Integrate protection into system architecture